


Have you ever wondered why some websites appear in the top search engine results while others are buried deep down? Understanding how search engines work can unlock this mystery!
So, how do search engines work? Three main SEO processes are involved: Crawling, Indexing, and Ranking. This article will discuss these steps and help you demystify the most fundamental search engine secrets. Let’s get started!
Crawling: How Search Engines Find Websites and Pages
Crawling is the first step to learning if you want to know how search engines work. It’s how it finds new pages and updates.
Search engines have robots (known as crawlers or spiders) that follow links from one page to another. Examples of popular search engine crawlers include Googlebot, Bingbot, and Yahoo Slurp.
Crawlers tirelessly roam the web, uncovering content to include in search results. This helps people find what they’re looking for whenever they’re on Google, Yahoo, etc.
Factors Affecting Crawl Frequency and Depth
Website Popularity
Search engines tend to crawl popular and well-designed websites more frequently and intensely. Popularity often indicates relevance and importance, prompting crawlers to visit more often.
Fresh Content
Populating your website with fresh content signals to crawlers that your pages are active and relevant. This freshness factor can lead to more frequent crawls as search engines strive to provide users with up-to-date information.
Site Structure
A well-organized and clear site structure makes it easier for crawlers to navigate through your pages. When your site structure is easy to understand, crawlers can efficiently index your content, potentially leading to deeper crawls.
Robots.txt Directives
Instructions in your robots.txt file tell crawlers which pages to crawl and which to avoid. By properly configuring this file, you can influence crawl behavior and ensure that crawlers focus on your site’s most essential pages.
Sitemap.xml
Providing a sitemap helps search engines understand your site’s layout and discover new content more efficiently. When search engines have a clear map of your website’s structure, they can conduct more thorough crawls, potentially reaching deeper into your site.
Server Performance
The performance of your website’s server can impact crawl frequency and depth. A fast and reliable server ensures that crawlers can access your content without delays, positively influencing how often and thoroughly your site is crawled.
Backlink Profile
Websites with many inbound links from reputable sources are crawled more frequently and deeply. Quality backlinks signal authority and importance, prompting search engines to pay more attention to your site.
Content Quality
High-quality, valuable content attracts crawlers and encourages them to delve deeper into your site. When your content is engaging, informative, and relevant, crawlers are more likely to index it thoroughly, potentially leading to more comprehensive crawls.
Crawl Budget
Search engines allocate resources based on the crawl budget assigned to your site. This budget influences how often and how deeply crawlers explore your website. By optimizing your site for crawl efficiency, you can make the most of your crawl budget and improve your site’s visibility in search results.
Crawl Budget
Search engines allocate resources based on the crawl budget allocated to your site, which can influence crawl frequency and depth.
Indexing: How Search Engines Store Website Data
Indexing is how search engines organize and store website information. It’s vital because it helps them quickly find and show relevant results to users.
When crawlers discover web pages, they store and organize them in their databases. They use keywords and other factors during this process. If they find duplicate content, they might only index one version to avoid cluttering search results with similar pages.
Factors Affecting the Indexing Process
Content Quality
Good content is more likely to be indexed than bad ones. Make sure your website content is relevant, well-written, and provides value to your audience.
Meta Tags and Titles
Properly optimized meta tags and titles help search engines know what your page is about, improving its chances of being indexed accurately.
Website Structure
A well-structured website with straightforward navigation makes it easier for algorithms to index your pages. Organize your content logically and use descriptive URLs.
Page Loading Speed
Websites that load faster tend to be indexed promptly. Optimize your website’s speed by compressing images, minifying code, and using caching techniques.
Mobile-Friendliness
With the increasing reliance on mobile devices, search engines prioritize mobile-friendly websites for indexing. Ensure your pages are responsive and provide a good user experience on all devices.
XML Sitemap
Providing an XML sitemap helps search engines discover and index all the pages on your website more efficiently. Include important pages and update the sitemap regularly.
Internal Links
Internal linking between pages on your website helps search engines discover and index new content. Ensure your internal links are relevant and natural.
External Links
Inbound links from reputable websites can help search engine algorithms discover and index your pages faster. Focus on getting quality backlinks from reliable sources.
Robots.txt and Noindex Tags
Use robots.txt and noindex tags strategically to control which pages search engines can index. This can prevent irrelevant or duplicate content from being indexed.
Canonical Tags
Canonical tags help search engines determine the preferred version of duplicate content. Use them to specify the original source of content and avoid indexing duplicates.
Content Freshness
Updating your content regularly signals to search engines that your website is active and relevant. Fresh content is more likely to be crawled and indexed frequently.
Ranking: How Search Engines Rate Websites
If indexing is how search engines organize and store website data, ranking is how they score it. This is the part where they decide the order in which websites appear in search results.
Ranking is crucial because it helps users quickly find the most relevant and valuable information. Search engine algorithms analyze factors like content quality, relevance, and authority to determine search result rankings.
Additionally, these algorithms constantly evolve to deliver better results, reflecting changes in user behavior and internet trends. This will impact how your website is ranked over time.
Factors Influencing Page Ranking in Search Results
Relevance
Your content should closely match what users are searching for. Use relevant keywords and provide valuable information directly addressing the user’s query.
Content Quality
High-quality content that is well-written, informative, and engaging tends to rank higher. Strive to make content that adds value to your readers and answers their questions.
Keywords
Strategic use of keywords in your content, title tags, meta descriptions, and headings helps search engines understand your page’s topic and improves its chances of ranking for relevant searches.
User Experience
A positive user experience, including fast page loading times, mobile-friendliness, and easy navigation, contributes to higher rankings. Also make sure your website is accessible and user-friendly.
Backlinks
Inbound links from other authoritative and reputable websites serve as stamps of approval for your content. They can improve your page’s authority and ranking. Focus on gaining quality links from relevant sources.
Page Authority
Your website’s overall authority and trustworthiness, as determined by factors like backlinks, content quality, and user engagement, influence your page’s ranking. Put more effort on improving your online presence and reputation.
Social Signals
Social media activity like likes, shares, and comments can indirectly impact your page’s ranking by increasing its visibility and engagement. Improve social sharing of your content to widen its reach.
Freshness
Fresh and up-to-date content ranks higher, especially for topics requiring current information or updates. Update your current content and publish new ones regularly to stay relevant in search results.
On-Page Optimization
Improving on-page elements like title tags, headings, meta descriptions, and alt texts with relevant keywords will help the algorithms understand the content of your page and improve its ranking potential.
Local SEO
For businesses targeting local audiences, factors like location data, business listings optimization, and local citations are crucial in ranking in local search results. Ensure your business information is up-to-date and accurate across online platforms.
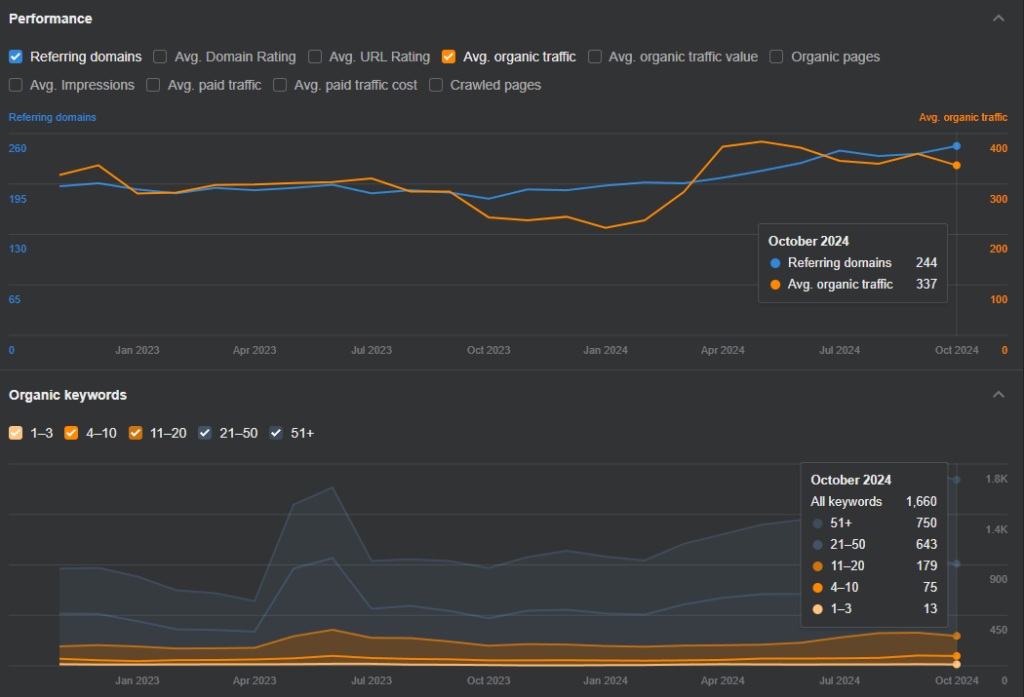
Frequently Asked Questions
Why is understanding how search engines work essential?
Understanding how search engines work helps you achieve higher search engine rankings for your website, attracting more organic traffic. By knowing about crawling, indexing, and ranking, you can make the right decisions to improve your website’s visibility and meet more potential customers online.
How can I improve my website’s crawl frequency and depth?
To improve crawl frequency and depth, focus on creating high-quality content, optimizing your website’s structure and navigation, and providing clear directives in your robots.txt file and sitemap.xml. Additionally, ensure your server is fast and reliable to accommodate frequent crawls by search engine bots.
What factors affect page ranking in search engine results?
Several factors influence page ranking, including relevance, content quality, backlinks, user experience, and social signals. By focusing on these aspects and continually improving your website’s authority and user engagement, you can improve your performance in SERPs and attract more organic traffic.
How do search engine algorithms impact page ranking?
Search engine algorithms constantly evolve to deliver users better and more relevant search results. To determine page ranking, these algorithms consider factors like content quality, relevance, user experience, and backlinks. Staying updated on algorithm changes and adapting your SEO strategies can help maintain or improve your website’s ranking over time.
So, How Does a Search Engine Work? Wrapping Up
Understanding how search engine algorithms crawl, index, and rank websites can help you improve your site’s visibility and attract more organic traffic. So best remember the factors above as you continue to optimize your pages.
If you want to learn more about how search engines work or enhance your website’s SEO and climb higher in search engine rankings, consider partnering with Reach Digital. Our team can help evaluate your website and create strategies to improve your online presence. Let’s work together to make your website shine in search results!


